
今天繼續 How Google does Machine Learning 的第二章節吧~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
第二章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
It's all about data
Framing an ML problem
Lab Intro - Framing an ML Problem
Framing an ML problem
Lab debrief
ML in applications
Demo: ML in applications
Pre-trained models
The ML marketplace is evolving
課程地圖
這章節就開始再講有關於資料的事情了,
首先我們要知道,很多資料是很難搞的,
例如下圖的例子:
你可能會想...這些資料有什麼特別的?
這些資料很多都是"在地的店名",
我們稱之為"hard queries, local queries"
而且人們搜尋這個並不是在找網站,而是在找地圖上的商家,
這時你會想一個個的替每家店寫一行新的code rule,
好讓你的搜尋找的到這家店嗎? 聽起來就很"笨拙"吧!
那我們來看看ML怎麼解決問題吧!
現在有個人對著google搜尋"coffee near me"
你看到了兩家店,你該怎麼推薦給他呢?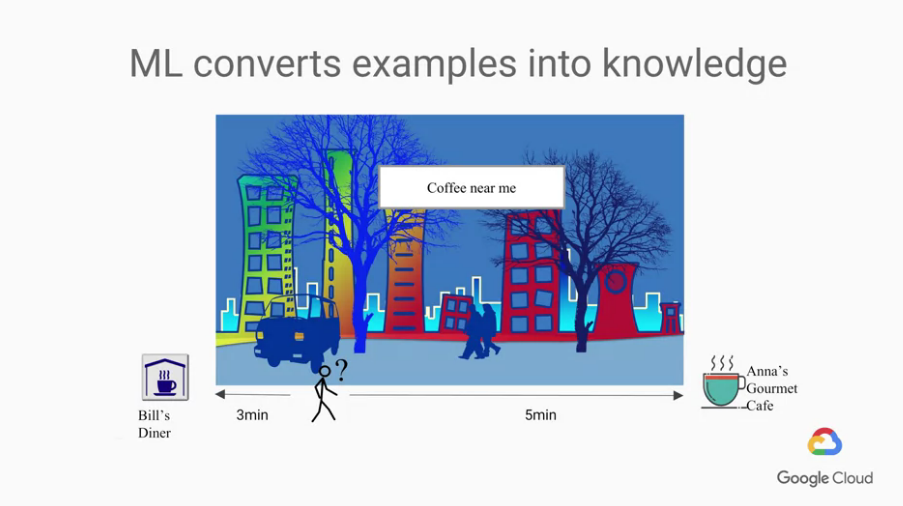
我們先來想想怎麼收集數據,使它成為ML問題,
ML背後的想法就是"蒐集一大堆例子,使這些變為知識並做未來的預測"
這問題中未來的預測是什麼?
很簡單,就是這兩家咖啡店的其中一家。
可是這問題的例子呢?
...... 太多種可能要考慮的點了
那你說我們如果要coding,你要將上述的問題全部變成一個個if的判斷條件式嗎?
所以google寧願讓用戶告訴我們,而不是google自己猜測並寫了一大堆rule,
我們用大量數據做權衡評估結果,而現在我們先將問題簡化成只考慮距離,
但資料怎麼來?
一開始還是以heuristics的方式為主,但google的心態是,
等到資料足夠時(有夠多的例子),就會拋棄heuristics的方法。
這裡的例子,就是我們前面所說的labeled data,
然後就開始蒐集資料,能整理出如下圖的結果,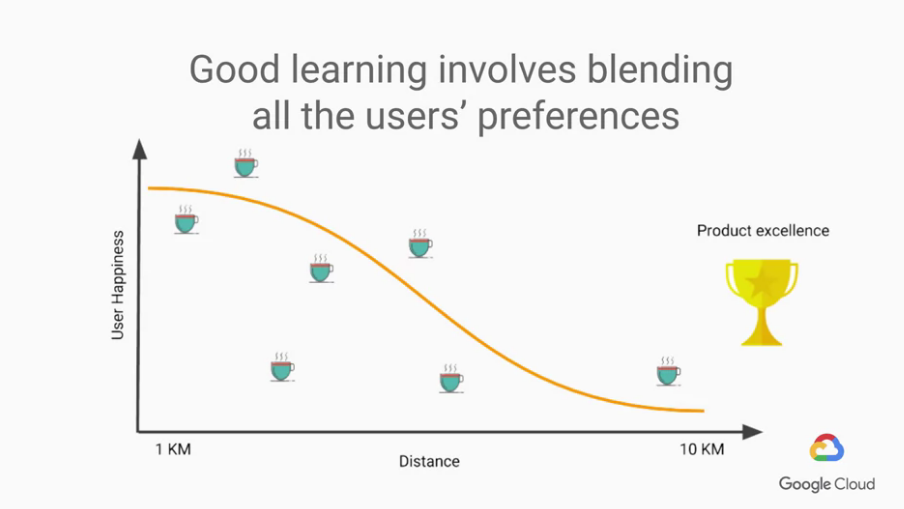
很明顯的我們就能看出,當咖啡店離我們越遠,越沒有人想去。
所以,ML就是關於收集適當data,
然後在良好學習與取得能信任的例子之間取得平衡。
課程地圖
這邊有個ML學習單(可以算是要做ML問題之前要想的心法了吧):
The first framing (maching learning problem)
-> If the use case was an ML problem....
- What is being predicted?
你將預測的東西是什麼,也就是你的答案"X"(label)- What data is needed?
你需要什麼數據呢? <- 非常多種data都有可能會有影響(大量各種的inputs)
The second framing (software probelm)
-> Now imagine the ML problem is a question of software
- What is the API for the problem during prediction?
我們需要透過API取得什麼樣的資料?- Who will use this service? How are they doing it today?
誰會使用這樣的服務? 這使用者今天在做什麼?
The third framing (data problem)
-> Lastly, cast it in the framework of a data problem. What are some key actions to collect, analyze, predict, and react to the data/predictions (different input features might require different actions)
- What data are we analyzing?
我們要分析什麼資料?- What data are we predicting?
我們要預測什麼?- What data are we reacting to?
當預測結果出來時,我們要做什麼反應?
課程地圖
舉例:Aucnet - 日本最大的實時汽車拍賣服務
以前是拍下多張照片上傳,
經銷商還要一一比對並指定汽車的型號與部分,非常耗時。
現在只要照著網站上的所說的上傳車子不同角度的照片,
資料只要足夠,透過ML就可以做到即時分析車子的各種資訊,
甚至還能估計出車子目前的售價範圍。
課程地圖
上章所提到的Aucnet,就是使用在GCP使用Tensorflow服務做成的。
最簡單的在我們的作品中使用ML的方法,就是使用Pre-trained models,

我們可以看見一般的訓練ML方法在左邊,
但右邊的Pre-trained ML models,
就是google都已經幫你訓練好了,可以直接拿這些ML模型使用。
舉例:Ocado - 網路最大線上雜貨店
但是越來越多客戶不想寫信,它們更希望的是直接交談。
(影片後面為Dialogflow的演示,以前打黑客松有稍微玩過一下,
也許之後有做這30天的Side Project可以再來玩一下這個?)
課程地圖

以下只說明技術部分:
他們提出的觀點是,現在ML這個領域也有分high level(高階)與low level(低階),
我們想做一個應用,以現在科技的成熟,也不一定要從low level(低階)出發。
雖然像上述一樣許多已經成熟的API可以直接使用非常方便,
不過不見得所有的應用都有像上述的API,
所以我們將從custom models開始教學,
畢竟市場上也必須有人為一些尚未有的功能建構出API,
而或許建構出那個API的人就會是你。 (感受到期待與壓力XD)
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
